Data Model
Status: Final
Willow is a system for giving meaningful, hierarchical names to arbitrary sequences of bytes (called payloads), not unlike a filesystem. For example, you might give the name blogidea1 to the bytestring Dear reader, I've got a great idea.
You also give the name blogidea2 to the bytestring (watch this space).

A little later you overwrite the existing entry at path blogidea2 with I've made a mistake. Willow tracks the timestamp of each assignment, and the new entry overwrites the old one.
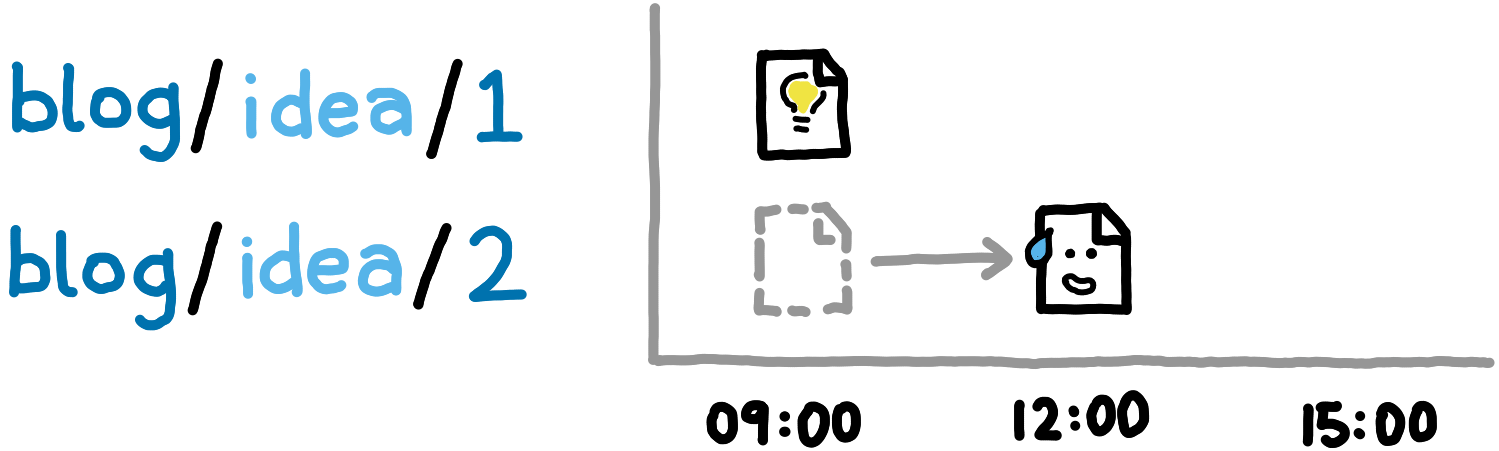
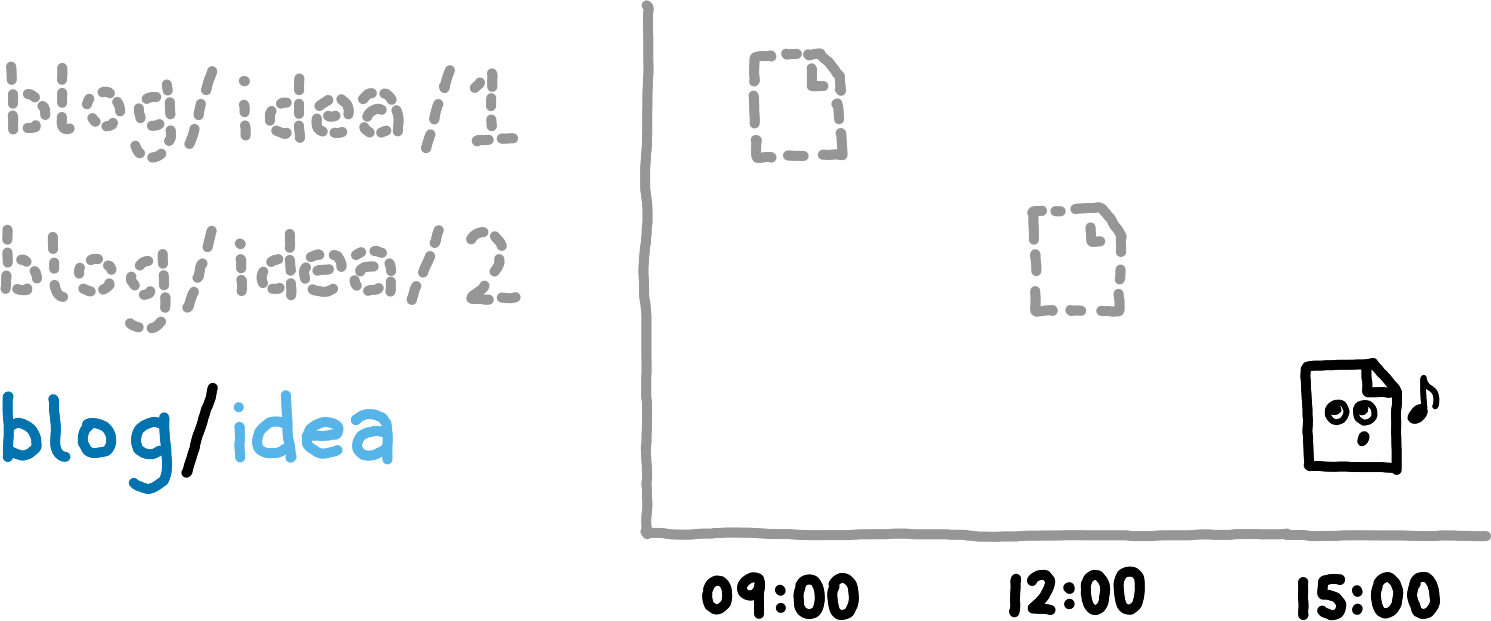
That night you decide it would be best if everyone forgot about the whole thing. By writing a new entry at blogidea, our previous entries are deleted. Think of it as overwriting a directory in a file system with an empty file. We call this mechanism prefix pruning.
Things would be rather chaotic if everyone wrote to the same blog. Instead, entries live in separate subspaces — intuitively, each user writes to their own, separate universe of data. Willow allows for various ways of controlling who gets to write to which subspace, from simple per-user access control to sophisticated capability systems.

Willow further allows the aggregation of subspaces into completely independent namespaces. Data from a public wiki should live in a separate namespace than data from a photo-sharing application for my family. Some namespaces should allow anyone to set up subspaces within them, others might require authorisation from a trusted manager. Willow offers a flexible mechanism for using different policies on a per-namespace basis.
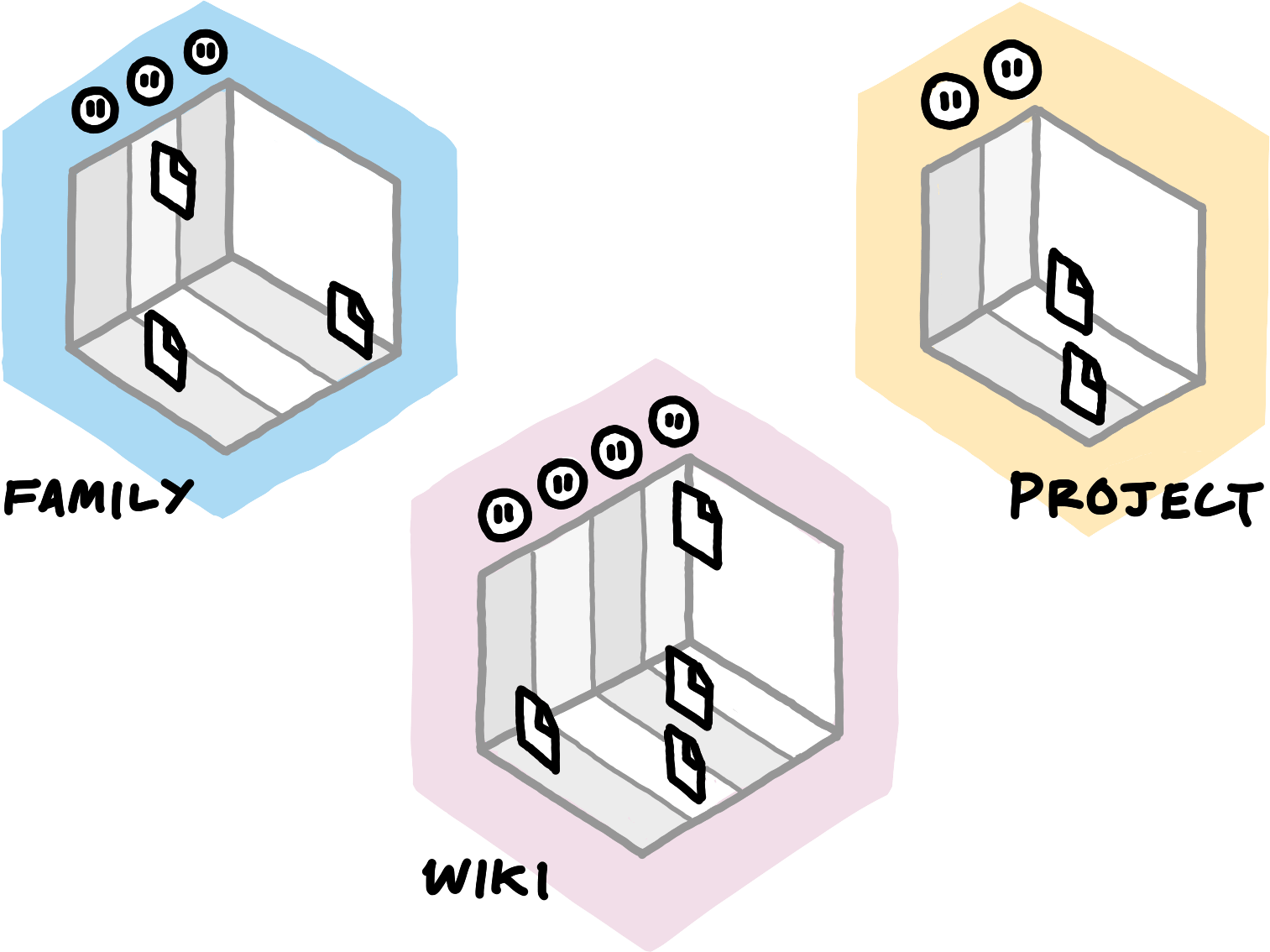
This constitutes a full overview of the data model of Willow. Applications read and write payloads from and to subspaces, addressing via hierarchical paths. Willow tracks timestamps of write operations, newer writes replace older writes in the manner of a traditional file system. These data collections live in namespaces; read and write access to both namespaces and subspaces can be controlled through a variety of policies.
Interactive Data Model
For the purposes of this demonstration we omit the concept of payload_digests.Some concepts are easier to understand by trying them out for yourself. We have created an interactive demonstration of how data between three peers is reconciled using the Willow Data Model.
Some suggested actions for experimenting with prefix pruning:
- Add a new Entry as Alfie at ideas and a timestamp of 110. What happens to the existing entry by Alfie at ideas?
- Add another Entry as Alfie at ideassong and a timestamp of 120. Can it coexist with the entry by Alfie at ideas?
- Add a new Entry as Alfie at ideas and a timestamp of 130. What happens to the existing entry by Alfie at ideassong?
A suggested action for experimenting with the concept of subspaces:
- Add a new Entry as Betty at notes and a timestamp of 110, and sync with Gemma. Is the existing entry by Gemma at notes overwritten?
Now that we could develop some intuition for the data model, we can almost delve into the precise definition of these concepts.
Parameters
Some questions in protocol design have no clear-cut answer. Should namespaces be identified via human-readable strings, or via the public keys of some digital signature scheme? That depends entirely on the use-case. To sidestep such questions, the Willow data model is generic over certain choices of parameters. You can instantiate Willow to use strings as the identifiers of namespaces, or you could have it use 256 bit integers, or urls, or iris scans, etc.
See Willow’25 for a default recommendation of parameters.This makes Willow a blueprint11You might call Willow a higher-kinded protocol, if you don’t mind being called a huge nerd in return. for concrete protocols: you supply a set of specific choices for its parameters, and in return you get a concrete protocol that you can then use. If different systems instantiate Willow with non-equal parameters, the results will not be interoperable, even though both systems use Willow.
We give precise semantics to these parameters in the spec proper, the list need not fully make sense on the first read-through.An instantiation of Willow must define concrete choices of the following parameters:
- A type NamespaceId for identifying namespaces.
- A type SubspaceId for identifying subspaces.
- A natural number max_component_length for limiting the length of path components.
- A natural number max_component_count for limiting the number of path components in a single path.
- A natural number max_path_length for limiting the overall size of paths.
- A totally ordered type PayloadDigest for content-addressing the data that Willow stores.
- Since this function provides the only way in which Willow tracks payloads, you probably want to use a secure hash function.A function hash_payload that maps bytestrings (of length at most ) into PayloadDigest.
- A type AuthorisationToken for proving write permission.
- Meadowcap is our bespoke capability system for handling authorisation. But any system works, as long as it defines a type of AuthorisationTokens and an is_authorised_write function.A function is_authorised_write that maps an Entry (defined later) and an AuthorisationToken to a Bool, indicating whether the AuthorisationToken does prove write permission for the Entry.
Concepts
Willow can store arbitrary bytestrings of at most bytes. We call such a bytestring a Payload.
A Path is a sequence of at most max_component_count many bytestrings, each of at most max_component_length bytes, and whose total number of bytes is at most max_path_length. The bytestrings that make up a Path are called its Components.
A Timestamp is a U64, that is, a natural number between zero (inclusive) and (inclusive). We highly recommendThis is merely a recommendation because an implementation neither can nor should gauge or enforce what users intended that 64-bit integer to mean. In particular, we can imagine plenty of scenarios where using a logical clock instead of physical time is appropriate. Please do prefer TAI over UNIX time though, because UNIX time handles leap seconds in an abhorrent way. to interpret Timestamps as microseconds in International Atomic Time (aka TAI) since the J2000 reference epoch (January 1, 2000, at noon, i.e., 12:00 TT).
The metadata associated with each Payload is called an Entry:
The metadata for identifying a Payload. The claimed creation time of the Entry.
Wall-clock timestamps may come as a surprise. We are cognisant of their limitations, and use them anyway. To learn why, please see Timestamps, really?
The length of the Payload in bytes. The result of applying hash_payload to the Payload.}A PossiblyAuthorisedEntry is a pair of an Entry and an AuthorisationToken. An AuthorisedEntry is a PossiblyAuthorisedEntry for which is_authorised_write returns true.
a is a prefix of a and of ab, but not of ab.A Path s is a prefix of a Path t if the first Components of t are exactly the Components of s. Conversely, we then call t an extension of s. The difference from s to t is the Path whose concatenation to s yields t. Any two Paths are related is one is a prefix of the other.
We can now formally define which Entries overwrite each other and which can coexist.
An Entry e1 is newer than another Entry e2 if
e1.timestamp > e2.timestamp, ore1.timestamp == e2.timestampand This comparison is why we require PayloadDigest to be totally ordered.e1.payload_digest > e2.payload_digest, ore1.timestamp == e2.timestampande1.payload_digest == e2.payload_digestande1.payload_length > e2.payload_length.
A store is a set of AuthorisedEntries such that
- all its Entries have the same namespace_id, and
- there are no two of its Entries old and new such that
old.subspace_id == new.subspace_id, andnew.pathis a prefixThis is the point where we formally define prefix pruning. ofold.path, and- new is newer than old.
When two peers connect and wish to update each other, they compute the joins of all their stores with equal NamespaceIds. Doing so efficiently and in a privacy-preserving way can be quite challenging, we recommend our Willow Confidential Sync protocol.Formally, adding a new Entry to a store consists of computing the join of the original store and a singleton store containing only the new Entry.The join of two stores that store Entries of the same namespace_id is the store obtained as follows:
- Start with the union of the two stores.
- Then, remove all Entries with a path p whose timestamp is strictly less than the timestamp of any other Entry of the same subspace_id whose path is a prefix of p.
- Then, for each subset of Entries with equal subspace_ids, equal paths, and equal timestamps, remove all but those with the greatest payload_digest.
- Then, for each subset of Entries with equal subspace_ids, equal paths, equal timestamps, and equal payload_digests, remove all but those with the greatest payload_length.
A namespace is the join over all22No matter in which order and groupings the stores are joined, the result is always the same. Stores form a join semi-lattice (also known as a state-based CRDT) under the join operation. stores in existence of a given NamespaceId. This concept only makes sense as an abstract notion, since no participant in a distributed system can ever be certain that it has (up-to-date) information about all existing stores. A subspace is the set of all Entries of a given SubspaceId in a given namespace. This again is more of a conceptual notion than a computer-friendly one.
Further Reading
The Willow data model stays fairly compact by deliberately sidestepping some rather important questions. In this section, we point to our answers for the most important ones.
How can we precisely delimit meaningful groups of Entries, for example, all recipes that Alfie posted on their blog in the past three months? Grouping Entries always incurs a tradeoff between expressivity (which sets of Entries can be characterised) and efficiency (how quickly a database can retrieve all its Entries of an arbitrary grouping). We present a carefully crafted selection of ways of grouping Entries here.
How should we encode the concepts of Willow for storage or network transmission? Due to the parameterised nature of Willow, there can be no overarching answer, but we cover some recurring aspects of the question here.
How should we select the AuthorisationToken and is_authorised_write parameters? Different deployments of Willow will have different needs. We provide Meadowcap, a capability-based solution that should be suitable for most use-cases.
How do we efficiently and securely compute joins over a network to synchronise data between peers? Again, different settings require different answers, but we provide the Confidential Sync protocol as a well-engineered, privacy-preserving solution that should be applicable to a wide range of scenarios.
How can we encrypt Entries while retaining the semantics of the original, unencrypted data? This question lies at the heart of end-to-end encryption for Willow, and we discuss our findings here.
How can a database provide efficient access to Entries? We give an introduction to the types of queries that a data store for Willow should support, and present some data structures for supporting them efficiently here.
