Encrypted Willow
 Willow has no built-in mechanisms for encrypting data. Still, it would be nice if peers (say, an always-on server in the cloud) could facilitate data exchange without being privy to the data they share. While it is straightforward to encrypt payloads, that still leaves the relays to learn about Entries, that is, all the metadata. In this document, we examine how we can protect this metadata.
Willow has no built-in mechanisms for encrypting data. Still, it would be nice if peers (say, an always-on server in the cloud) could facilitate data exchange without being privy to the data they share. While it is straightforward to encrypt payloads, that still leaves the relays to learn about Entries, that is, all the metadata. In this document, we examine how we can protect this metadata.
Unfortunately, we cannot simply encrypt all the fields of Entries, because peers need to access this data to determine which Entries overwrite which others. More precisely, peers need the ability to compute joins of stores. These well-defined concepts give us precise limits on which properties of which metadata we have to preserve, and which properties we can vigorously scramble.
Typically, you would use symmetric encryption to achieve confidentiality — the core data model can provide authenticity via AuthorisationTokens already. As for the granularity at which to use different keys, we consider three relevant options: a key per namespace, a key per subspace, or a key per combination of subspace and Path11We describe a system based on key derivation for each successive Path Component in the section on encrypting paths..
Payload Digest and Length
When a peer stores a Payload, it automatically knows its length and it can compute its digest. Hence, there is little point in encrypting payload_length and payload_digest.
On the bright side, the Payload itself need not be a plaintext document. One can append a nonce to each plaintext (so that equal plaintexts at different paths have different digests22Salting with nonces is not necessary when using different encryption keys per Path.), apply some padding to a prespecified length (so that the length of the plaintext is not leaked), encrypt the result (so that the contents stay confidential), and use the resulting cyphertext as a Payload.
Anyone who can decrypt this Payload can recover the original plaintext, but to anyone else, the Payload and the associated payload_length and payload_digest are essentially meaningless. Yet, such peers can still store and replicate the Entry and its Payload.
Timestamp
Computing joins of stores necessitates comparing Timestamps numerically. This does not mesh well with encryption; encrypted data is supposed to be indistinguishable from random data, but preserving relative ordering is very much non-random. Hence, we begrudingly accept that Willow deals in plaintext Timestamps only.
The privacy-conscious user might still choose to obscure their Timestamps, as Timestamps need not reflect actual creation time after all. One option could be to downgrade the resolution to individual days, in order to obscure timezonesThere is some prior art on obfuscating timestamps with git.. When writing to a subspace from a single device only, one could even use Timestamps as a logical counter by incrementing the timestamp of each successive Entry by one, fully preserving the deletion semantics of accurate timestamps while completely obscuring physical time.
We hope to see software libraries emerge that make it easy for users to select an appropriate degree of obfuscation.
NamespaceId and SubspaceId
If NamespaceIds or SubspaceIds were encrypted differently per subspace, then Entries that should overwrite each other might not do so. Encrypting them on a per-namespace basis has no effect on the inferences that an observer can make about which Entries are part of the same namespaces or subspaces. Hence, there is little reason to encrypt them at all.
Any non-random-looking information that is part of NamespaceIds or SubspaceIds should then be considered as public, but this is easily solved by hashing the meaningful parts of the Ids before passing them on to Willow. This is computationally less expensive than encrypting them.
Path
Paths are arguably the most interesting facet of encryption in Willow. Since users (or their applications) deliberately select Paths to enable meaningful data access, Paths carry information that clearly should be encrypted.
Because Entries in the same subspace overwrite each other based on their paths, the cyphertexts of two Paths that begin with some number of equal Components must begin with as many equal Components as well. Such prefix-preserving encryption schemes (Fan et al., 2004) are well-understood, and leak less information than order-preserving encryption schemes (Li & Omiecinski, 2005).
The hierarchical nature of Paths suggests another requirement: it should be possible to convey the ability to decrypt all Entries whose path starts with a particular prefix. For example, allowing somebody to decrypt blogideas should allow them to decrypt blogideasgame.txt and blogideaspetsmaze.txt as well, but neither blogconfig.txt nor codewillow.rs.
We can achieve both hierarchic decryption capabilities and prefix-preservation by encrypting individual Components with encryption keys that we successively derive with a key derivation function. Let kdf be a key-derivation function that takes as inputs an encryption key and a byte string of length at most max_component_length, and that returns a new encryption key.A suitable candidate for kdf is HKDF (RFC 5869), using successive Components as the salt of each derivation step. Let encrypt_component be a function that encrypts a single Component with a given encryption key. Given an initial key key_0, we can then encrypt Paths as follows:
- Encrypting the empty Path yields the empty Path again.
- Encrypt a Path with a single Component component_0 as
encrypt_component(key_0, component_0). - For any other (longer) Path , denote its final Component as component_ipp, the Path formed by its prior Components as path_i, the final component of path_i as component_i, and denote the key that is used to encrypt component_i as key_i. You then encrypt the Path by first encrypting path_i, and then appending
encrypt_component(kdf(key_i, component_i), component_ipp).
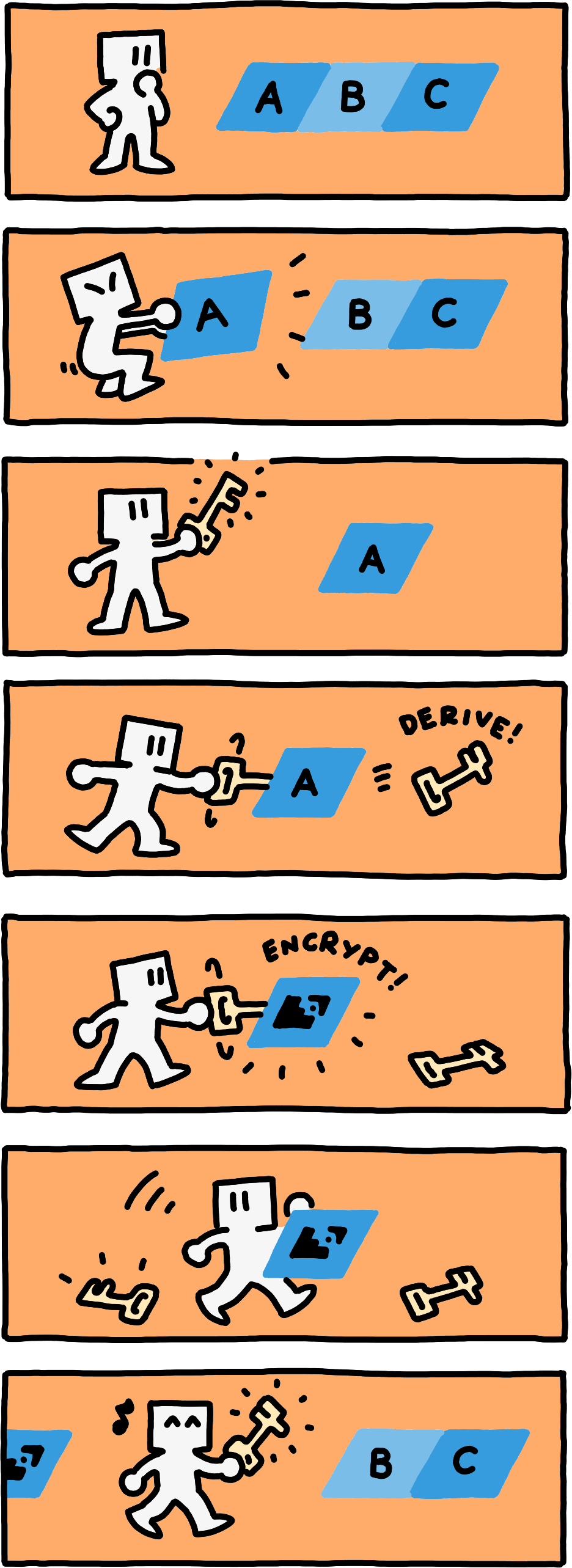 A Path is encrypted Component by Component.
A Path is encrypted Component by Component.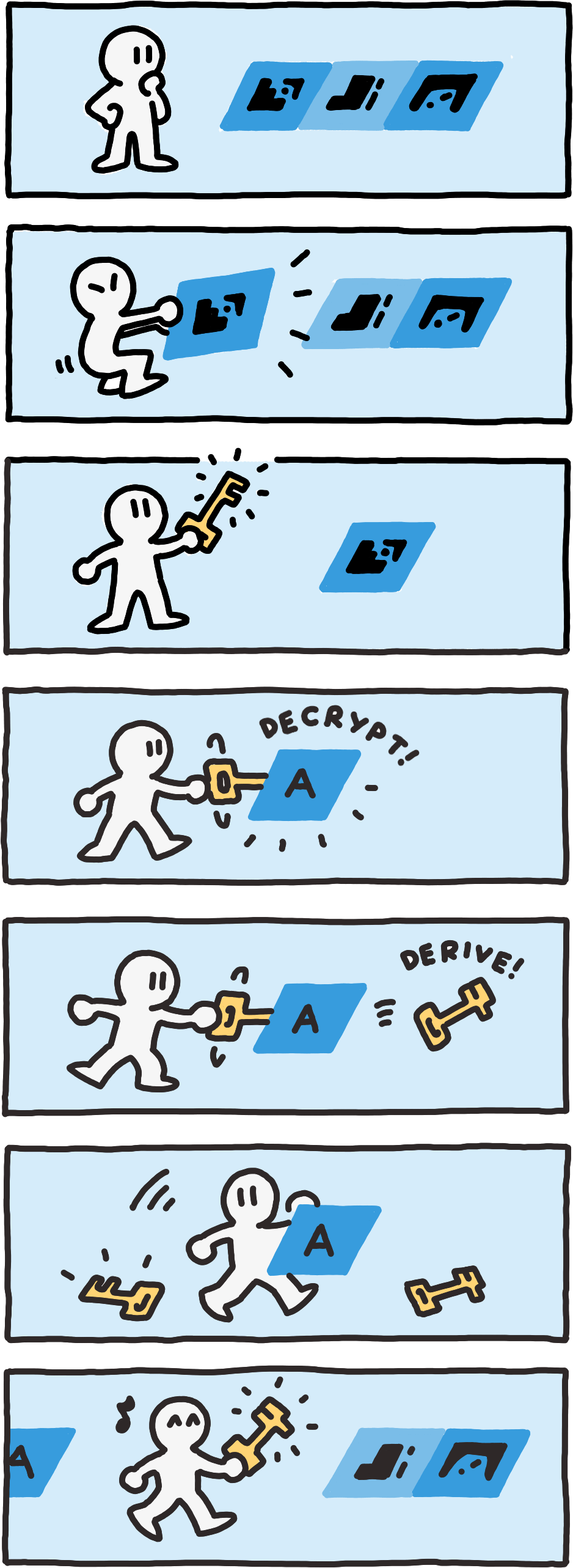 A Path is decrypted Component by Component.
A Path is decrypted Component by Component.This technique produces prefix-preserving cyphertexts, and it lets anyone who can decrypt a certain Path also decrypt all extensions of that Path. As long as the kdf is non-invertable even for known Components, no other Paths can be decrypted beyond the point where they differ.
Giving the ability to decrypt all Paths starting with some Path p requires three pieces of information: the plaintext of p, the cyphertext of p, and the encryption key that is used for encrypting Paths that have exactly one more Component than p.
When encrypting payloads, you can use the same key that encrypts the final Component of an Entry’s path for encrypting the Entry’s Payload as well (leaving Payloads at the empty Path unencrypted). This scheme then conveys the same hierarchical decryption capabilities as those for Paths.
Finally, we want to note that this style of encrypting Paths can be implemented completely transparently. Applications specify Paths in the clear, and a thin translation layer encrypts them before passing them to Willow, and decrypts Paths before handing them from Willow to the applications. Internally, Willow does not need to be aware of this. Protocols like Meadowcap or Confidential Sync just work with the encrypted Paths.
AuthorisationToken
Peers store and exchange not only Entries but AuthorisedEntries. Whether AuthorisationTokens can be meaningfully encrypted depends on the choice of is_authorised_write, and should be taken into account when designing and using these parameters. Meadowcap McCapabilities cannot be encrypted, as this would remove the ability of peers without access to the decryption keys to verify the signatures.